








3 Methods to Set Up a Reverse Proxy on a Home Network
Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29
Learn More
Learn to rotate proxies in Scrapy efficiently with our step-by-step guide. Avoid IP bans, bypass rate limits, and scrape data seamlessly using rotating proxies. Includes examples and best practices.
Scrapy is a flexible framework written in Python. It is widely used in web scraping when IP bans, rate limits, or even blocks are often triggered. Scrapy rotating proxies offer an effective solution for these challenges.
This blog will explore why and how rotating proxies for web scraping. There are also some tips and practices for higher efficiency.
As websites are increasingly smart in detecting bots and scrapers, using a single IP address for all requests is not enough anymore. Many websites employ advanced anti-scraping measures that can easily detect and block repeated requests from the same IP. Such as:
By rotating proxies, you can distribute your requests across different IP addresses to avoid detecting scraping activity. This helps avoid IP bans to scrap smoothly. Key benefits:
Scrapy allows you to integrate proxy rotation through middleware.
Step 1: Install the Scrapy Rotating Proxies Package
To proxy rotation in Scrapy, first please install the scrapy-rotating-proxies package. This middleware simplifies the management of multiple proxies, handles proxy rotation automatically, and saves you from manually cycling through proxy lists.
You can install this package using:

For copy:
pip install scrapy-rotating-proxies
Step 2: Enable Proxy Middleware in Scrapy Settings
Enable the proxy middleware in Scrapy’s settings file (settings.py). This middleware will handle the proxy rotation process.
Add the following lines to your settings.py file:
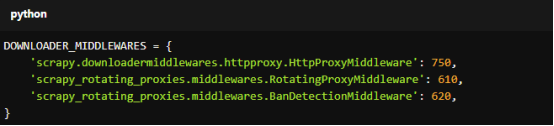
For copy:
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy_rotating_proxies.middlewares.RotatingProxyMiddleware': 610,
'scrapy_rotating_proxies.middlewares.BanDetectionMiddleware': 620,
}
Step 3: Add Your Proxy List
Add a list of proxies that Scrapy will rotate through. You can use free proxies, but they are often unreliable and frequently blocked. For optimal results, consider using high-quality paid proxies, such as rotating residential proxies, which offer higher anonymity and better success rates. High-quality paid proxies can avoid frequent bans and ensure better success rates.
Add the following line to your settings.py file to define your proxy list:
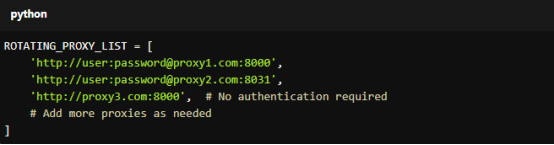
For copy:
ROTATING_PROXY_LIST = [
'http://user:[email protected]:8000',
'http://user:[email protected]:8031',
'http://proxy3.com:8000', # No authentication required
# Add more proxies as needed
]
Step 4: Configure Proxy Rotation Settings
Scrapy allows users to fine-tune how proxy rotation happens. For example, you can set the number of retries for failed requests or specify how often proxies should rotate.
Here are some useful settings that you can add to settings.py:

For copy:
ROTATING_PROXY_PAGE_RETRY_TIMES = 5 # Retry a proxy 5 times before giving up
ROTATING_PROXY_CLOSE_SPIDER = False # Keep the spider running even if all proxies fail
Step 5: Test the Proxy Rotation
Once you’ve configured the proxy rotation middleware, it’s time to test if everything works correctly. You can create a simple Scrapy spider to scrape a website like httpbin.org (which returns your IP address) to verify that the proxies are rotating.
Here’s an example spider to test proxy rotation:
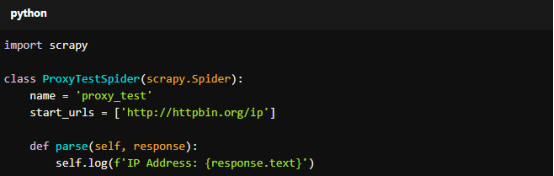
For copy:
import scrapy
class ProxyTestSpider(scrapy.Spider):
name = 'proxy_test'
start_urls = ['http://httpbin.org/ip']
def parse(self, response):
self.log(f'IP Address: {response.text}')
Run the spider using:

For copy:
scrapy crawl proxy_test
Let’s now look at an example to solidify the above. Suppose you want to scrape job listings from a website like LinkedIn, known for blocking scrapers aggressively. Using rotating proxies, you can scrape data without getting your IP banned.

Example Scrapy Spider with Rotating Proxies
In the example below, we’re scraping a fictional job board that aggressively blocks scrapers. By implementing rotating proxies, our spider can gather job listing data without being blocked. Each request will use a different proxy from our proxy pool to avoid detection.
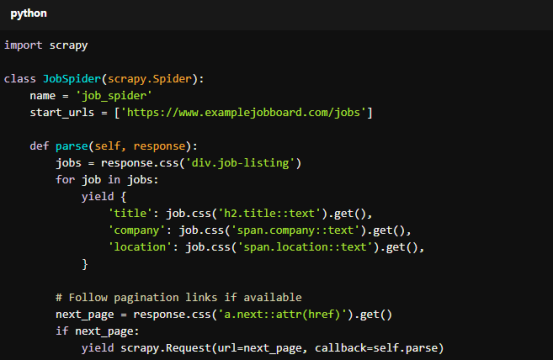
For copy:
import scrapy
class JobSpider(scrapy.Spider):
name = 'job_spider'
start_urls = ['https://www.examplejobboard.com/jobs']
def parse(self, response):
jobs = response.css('div.job-listing')
for job in jobs:
yield {
'title': job.css('h2.title::text').get(),
'company': job.css('span.company::text').get(),
'location': job.css('span.location::text').get(),
}
# Follow pagination links if available
next_page = response.css('a.next::attr(href)').get()
if next_page:
yield scrapy.Request(url=next_page, callback=self.parse)
With proxy rotation enabled through the configuration in settings.py, this spider will automatically rotate proxies for each request, reducing the risk of getting blocked.
While rotating proxies can significantly improve your scraping efficiency, there are certain best practices to ensure smooth operation and avoid common pitfalls.
1. Use High-Quality Proxies
Free proxies do look attractive, but they are often slow, less secure, and more likely to be flagged or even blocked. Paid proxies, especially rotating residential proxies, offer better reliability, speed, and anonymity. They look like IPs from real users, making them harder to detect and block. For consistent and large-scale scraping, look for proxies with high uptime.
2. Rotate User Agents Along with Proxies
Besides rotating proxies, rotating user agents can further disguise your scraping activity. The user agent string identifies the browser and operating system. By changing it, you can make each request appear as if from a different device and browser. Harder for websites to detect scraping patterns. Scrapy has a built-in way to do this through the scrapy-fake-useragent package.
Here’s how to install it:

For copy:
pip install scrapy-fake-useragent
Then add it to your DOWNLOADER_MIDDLEWARES in settings.py:

For copy:
DOWNLOADER_MIDDLEWARES.update({
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
})
3. Set Crawl Delays
Even with rotating proxies, making too many requests in a short period can raise red flags on the target website. Set a crawl delay in Scrapy to avoid server overload.

For copy:
DOWNLOAD_DELAY = 2 # Delay of 2 seconds between requests
4. Monitor Response Codes
Track HTTP response codes to identify when proxies block (e.g., receiving 403 or 429 errors). Set up Scrapy to retry requests with a different proxy if a block is detected.

For copy:
HTTPERROR_ALLOWED_CODES = [403, 429]
Scrapy rotating proxies are critical for scraping websites at scale. They provide anonymity, avoid IP bans, and allow you to scrape data efficiently without interruptions. By following the above steps, you can easily integrate rotating proxies into your Scrapy projects and enjoy smooth data collecting.
Ready to supercharge your web scraping projects with rotating proxies? MacroProxy offers high-quality rotating residential and datacenter proxies designed to keep your scraping operations running smoothly. Try our proxies today with a free trial and experience worry-free scraping with unbeatable performance.
< Previous
Next >

Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29

Discover top web scraping tools for 2025, comparing features, proxy integration, and scalability to optimize your data extraction efforts.
Post Time:2025-04-25
Explore web scraping with JavaScript: tools, steps, and MacroProxy solutions for dynamic data extraction.
Post Time:2025-04-18