








3 Methods to Set Up a Reverse Proxy on a Home Network
Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29
Learn More
Learn how to scrape YouTube videos safely using proxies and IP rotation. Discover data scraping techniques, ethical considerations, and best practices.
Scraping data from YouTube can be a powerful way to gather insights about videos, channels, comments, and metadata, especially for video marketing. However, to protect its users, YouTube has strict anti-bot measures. Accessing its data at scale can lead to IP bans or CAPTCHAs. Using proxies can help bypass these restrictions and scrape YouTube efficiently and safely.
In this guide, we’ll cover step-by-step introductions on how to scrape YouTube videos while using proxies to IP rotation to ensure anonymity, avoid detection, and gather data effectively.

At the very beginning, let's figure out what data you can scrape from YouTube before technical setup.
Below we list common use cases:
Besides these benefits, legal and ethical considerations also exist when scraping.
Scraping YouTube data may violate its Terms of Service, please read it before scraping to ensure adherence. Improper use of proxies could lead to account bans or legal issues. Comply with applicable laws and use the data ethically. If possible, consider using YouTube’s official API for data collection as a more compliant alternative, which provides structured access to video data, including metadata and captions.
YouTube monitors traffic and IP to detect unusual patterns, for example, repeated requests from the same IP address in a short period. Using proxies can rotate IPs, which is beneficial:
Thus you can successfully avoid detection and blocking when scraping.
To scrape YouTube effectively while using proxies, follow the steps below:
Python is one of the most popular programming languages for web scraping. Install Python and the following libraries:
Install these libraries using pip:

For Copy:
pip install requests beautifulsoup4 pytube lxml
To rotate IP addresses, you’ll need a proxy service. Popular proxy providers include:
Notice:
You can also use free proxies, but they are often unreliable and may compromise your security. Please choose a reputable paid service if requiring reliable performance and security, especially for critical tasks.
Proxies come in different types. For YouTube scraping, you can consider the following choices:
Assigned to real devices, making them harder to detect. Ideal for YouTube scraping.
Fast and cost-effective but easier to detect. Use cautiously.
Automatically change IPs after each request, reducing the risk of detection.
For optimal performance, we recommend you choose rotating residential proxies. MacroProxy offers affordable and quality residential proxies, and global 95M+ ISPs for your rotating. Ask for a test chance and experience today.
Here’s an example of a Python script to scrape YouTube video metadata using proxies:
Code Example: Scraping YouTube Video Metadata
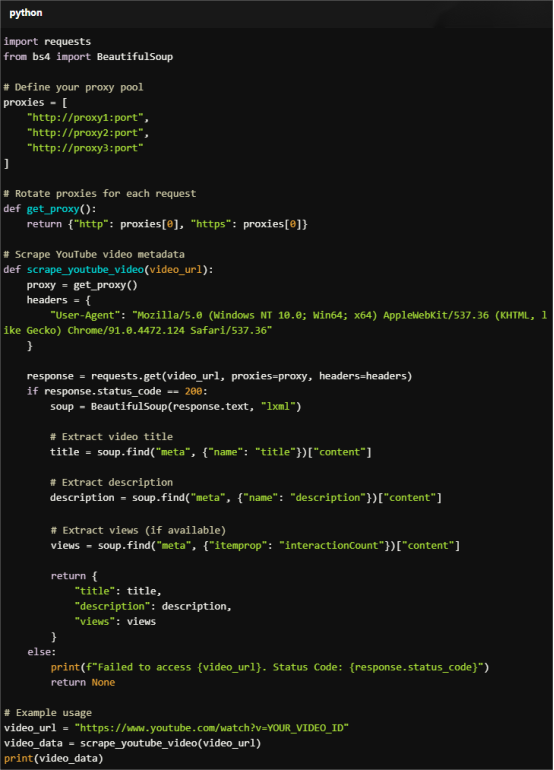
For Copy:
import requests
from bs4 import BeautifulSoup
# Define your proxy pool
proxies = [
"http://proxy1:port",
"http://proxy2:port",
"http://proxy3:port"
]
# Rotate proxies for each request
def get_proxy():
return {"http": proxies[0], "https": proxies[0]}
# Scrape YouTube video metadata
def scrape_youtube_video(video_url):
proxy = get_proxy()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
response = requests.get(video_url, proxies=proxy, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "lxml")
# Extract video title
title = soup.find("meta", {"name": "title"})["content"]
# Extract description
description = soup.find("meta", {"name": "description"})["content"]
# Extract views (if available)
views = soup.find("meta", {"itemprop": "interactionCount"})["content"]
return {
"title": title,
"description": description,
"views": views
}
else:
print(f"Failed to access {video_url}. Status Code: {response.status_code}")
return None
# Example usage
video_url = "https://www.youtube.com/watch?v=YOUR_VIDEO_ID"
video_data = scrape_youtube_video(video_url)
print(video_data)
To avoid detection, rotate IP addresses after a set number of requests or between each request. Here’s how to implement proxy rotation:
Code Example: Adding Proxy Rotation
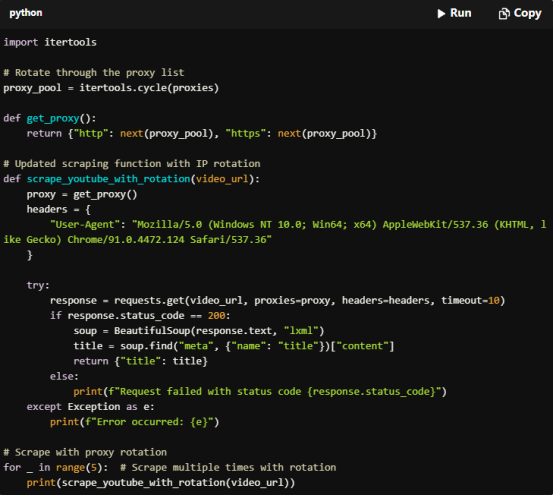
For Copy:
import itertools
# Rotate through the proxy list
proxy_pool = itertools.cycle(proxies)
def get_proxy():
return {"http": next(proxy_pool), "https": next(proxy_pool)}
# Updated scraping function with IP rotation
def scrape_youtube_with_rotation(video_url):
proxy = get_proxy()
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
try:
response = requests.get(video_url, proxies=proxy, headers=headers, timeout=10)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "lxml")
title = soup.find("meta", {"name": "title"})["content"]
return {"title": title}
else:
print(f"Request failed with status code {response.status_code}")
except Exception as e:
print(f"Error occurred: {e}")
# Scrape with proxy rotation
for _ in range(5): # Scrape multiple times with rotation
print(scrape_youtube_with_rotation(video_url))
YouTube may present CAPTCHA challenges if it detects bot-like behavior. Use these strategies to bypass CAPTCHAs:
1. Respect YouTube’s Terms of Service
Scraping data may violate YouTube’s terms. Always use the data responsibly.
2. Use High-Quality Proxies
Free proxies are often blacklisted by YouTube. Invest in reliable residential or rotating proxies.
3. Throttle Requests
Avoid sending too many requests in a short time to prevent triggering anti-bot systems.
4. Combine with User-Agent Rotation
Use libraries like fake_useragent to rotate headers and mimic different devices/browsers.
YouTube allows web scraping of publicly available data without violating its terms of service. Avoid scraping their content without permission, or it can lead to account bans or legal action.
Rrotating residential proxies are often the best choice.
For scraping YouTube, we recommended rotating IPs every 5-10 requests or every 10-20 minutes. And maintain a low request rate (1 request per 5-10 seconds) to minimize the risk of detection and blocking.
a. Add delays between requests to mimic human behavior. For example, 5-10 seconds.
b. Use Libraries like fake_useragent to different "User-Agent" headers for each request.
c. Use CAPTCHA solvers, such as 2Captcha or Anti-Captcha, to automatically solve.
d. Implete IP rotation to avoid triggering detection systems.
e. Scrape data in smaller batches rather than sending a large volume of requests at once.
Yes, here are two popular methods to do so.
Method 1. Using YouTube's API: Retrieve video details, including captions (subtitles). This is the most compliant and recommended approach.
Method 2. Web Scraping: Access the transcript (if available) through the page's HTML. This involves parsing the page content with libraries like BeautifulSoup in Python.
Below is a basic example
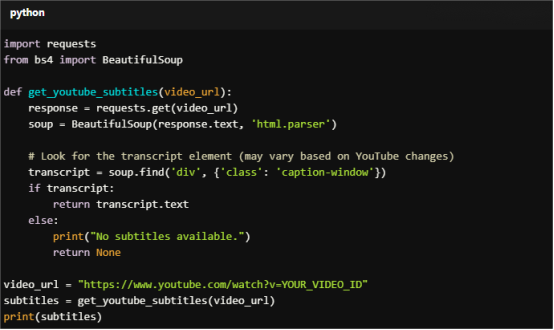
For Copy:
import requests
from bs4 import BeautifulSoup
def get_youtube_subtitles(video_url):
response = requests.get(video_url)
soup = BeautifulSoup(response.text, 'html.parser')
# Look for the transcript element (may vary based on YouTube changes)
transcript = soup.find('div', {'class': 'caption-window'})
if transcript:
return transcript.text
else:
print("No subtitles available.")
return None
video_url = "https://www.youtube.com/watch?v=YOUR_VIDEO_ID"
subtitles = get_youtube_subtitles(video_url)
print(subtitles)
Using proxies and Python is an efficient way to scrape YouTube videos, you can gather data while maintaining anonymity. By following the steps in this guide, you can implement proxies, rotate IPs, and scrape YouTube safely and effectively. Please always use high-quality proxies, handle CAPTCHAs, and respect YouTube’s terms to avoid potential issues. Buy high quality rotating residential proxies to maximize the success of your scraping if necessary.
If your project requires large-scale data collection, consider using YouTube’s official API as a more reliable and ethical alternative.
Happy scraping!
< Previous
Next >

Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29

Discover top web scraping tools for 2025, comparing features, proxy integration, and scalability to optimize your data extraction efforts.
Post Time:2025-04-25
Explore web scraping with JavaScript: tools, steps, and MacroProxy solutions for dynamic data extraction.
Post Time:2025-04-18