








3 Methods to Set Up a Reverse Proxy on a Home Network
Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29
Learn More
Learn how to effectively scrape data from X (Twitter) using the API and Python.
Want to analyze trends, track conversations, or gather insights from Twitter? Who's engaging with whom, to where they're tweeting from. In this guide, we’ll show you how to scrape Twitter data using Python, APIs, and web scraping techniques. Help you extract tweets, user profiles, hashtags, and more—legally and efficiently.

X (formerly Twitter) is one of the world’s most influential social media platforms. Millions of users share real-time updates, news, and opinions. With its vast user base and diverse content, X is a valuable resource for gathering insights, analyzing trends, and engaging with audiences.
However, extracting data from X isn’t always easy due to:
Data scraping, also known as web scraping, is the automated process of extracting information from the web. It involves using software tools or scripts to gather publicly available data, allowing users to collect large volumes of information quickly and efficiently for analysis and decision-making. However, it is crucial to approach scraping responsibly and ethically.
Scraping Twitter data is subject to its Terms of Service.
Always check Twitter’s latest policies before scraping data to avoid legal risks.
1. Market Research: Gaining an edge over your competitors is essential in the competitive business environment. By Twitter scraping, you gain a comprehensive overview of the market terrain, enabling strategic planning. Think of it as having a covert agent within your competitors' domain, furnishing you with invaluable intelligence to secure a competitive advantage.
2. Customer Feedback Analysis: You can delve deep into your customers' psyche by Twitter scraping. Understanding what your customers discuss, their preferences, aversions, and challenges becomes achievable through the collection and analysis of posts. This vast pool of data aids in customizing your products or services to better align with their requirements, resulting in heightened customer satisfaction and improved sales performance.
3. Trend Analysis: Analyzing the popular hashtags and viral posts through X scraping can boost your marketing strategies. This approach helps pinpoint the type of content that connects with your desired audience. Additionally, leveraging an X scraper allows you to gather valuable insights on the top X influencers within your industry.
Depending on your requirements and the methods used, you can extract various types of data:
1. Tweets: Textual tweets’ content(including hashtags, mentions, and links), metadata, Engagement Metrics(Number of retweets, likes, and replies) .
2. User Profiles: User public information(usernames, bios, profile pictures, account creation dates, etc), follower and following counts, and locations.
3. Hashtags and Trends: Trending topics and hashtags usage.
4. Media Attachments: Images, videos, and links.
5. Engagement and Interaction Data: Mentions, replies, comments, and poll data.
There are two main ways to scrape Twitter:
1. Using the Twitter API (Recommended) – The safest method, but requires API keys and follows rate limits.
2. Web Scraping (Risky) – Extracts data directly from Twitter’s website but may lead to bans.
| Method | Pros | Cons |
| Twitter API | Official, reliable, avoids bans | Requires API keys, limited data access |
| Web Scraping | No API key needed, full-page access | Risk of bans, legal concerns |
1. Create a Twitter Developer Account
Go to the Twitter Developer Portal and register a developer account.
2. Create a project & app
Get your API Key, API Secret, and Bearer Token.
3. Install Tweepy

For Copy:
pip install tweepy
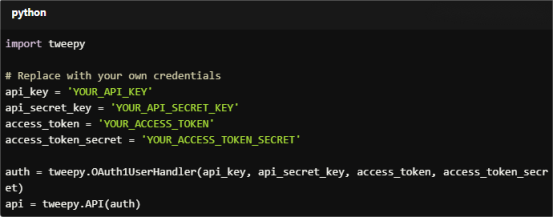
4. Authenticate to Twitter API
Use your API keys to authenticate and access Twitter’s data.
Example code
For Copy:
import tweepy
# Replace with your own credentials
api_key = 'YOUR_API_KEY'
api_secret_key = 'YOUR_API_SECRET_KEY'
access_token = 'YOUR_ACCESS_TOKEN'
access_token_secret = 'YOUR_ACCESS_TOKEN_SECRET'
auth = tweepy.OAuth1UserHandler(api_key, api_secret_key, access_token, access_token_secret)
api = tweepy.API(auth)
5. Scrape Tweets
You can scrape tweets containing specific keywords, hashtags, or from specific users.
Example code to scrape tweets containing a specific hashtag

For Copy:
for tweet in tweepy.Cursor(api.search_tweets, q='#YourHashtag', lang='en').items(100):
print(f"{tweet.user.screen_name}: {tweet.text}")
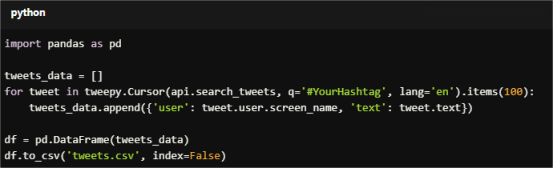
6. Store Data
Save the scraped data into a CSV file or a database for further analysis.
For Copy:
import pandas as pd
tweets_data = []
for tweet in tweepy.Cursor(api.search_tweets, q='#YourHashtag', lang='en').items(100):
tweets_data.append({'user': tweet.user.screen_name, 'text': tweet.text})
df = pd.DataFrame(tweets_data)
df.to_csv('tweets.csv', index=False)
If you need data that is not available through the API, you can scrape the Twitter web page directly.
1. Install Beautiful Soup and Requests

For Copy:
pip install beautifulsoup4 requests
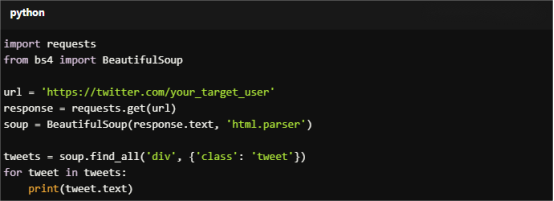
2. Scrape Data
Use Requests to get the HTML content and Beautiful Soup to parse it.
Example code
For Copy:
import requests
from bs4 import BeautifulSoup
url = 'https://twitter.com/your_target_user'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tweets = soup.find_all('div', {'class': 'tweet'})
for tweet in tweets:
print(tweet.text)
1. Install Selenium

For Copy:
pip install selenium
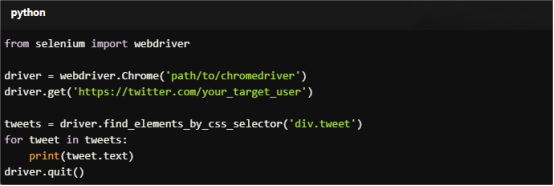
2. Set Up WebDriver
Download a suitable WebDriver for your browser (e.g., ChromeDriver for Chrome).
Example code
For Copy:
from selenium import webdriver
driver = webdriver.Chrome('path/to/chromedriver')
driver.get('https://twitter.com/your_target_user')
tweets = driver.find_elements_by_css_selector('div.tweet')
for tweet in tweets:
print(tweet.text)
driver.quit()
To scrape Twitter data without coding, you can explore a range of user-friendly tools and platforms. Here are some options for Twitter scraping without writing any code:
Octoparse is a powerful Twitter web scraping tool, suitable for users of all skill levels, from beginners to advanced users. Octoparse offers both free and paid plans. The free plan is for small, simple projects while the paid plan is for small teams or businesses.
Features:
1. Drag-and-drop interface.
2. Pre-built templates for scraping Twitter.
3. Cloud-based scraping and scheduling.
How to Use:
1. Sign up for an Octoparse account.
2. Use the pre-built Twitter template or create a new task.
3. Define the data you want to scrape (e.g., tweets, user profiles).
4. Run the task and download the data.
ParseHub is a web scraping tool with a visual interface. It’s designed to handle websites with dynamic content such as using AJAX, JavaScript, and other complex web technologies. ParseHub offers a free plan that allows users to scrape twitter data with limitations on the number of pages and frequency. Users can upgrade to a paid plan for access to more features.
Features:
1. Visual point-and-click interface.
2. Handles dynamic content and AJAX.
3. Cloud-based with scheduling options.
How to Use:
1. Sign up for a ParseHub account.
2. Create a new project and enter the Twitter URL.
3. Use the point-and-click interface to select the data elements.
4. Run the project and export the data in various formats.
DataMiner is a browser extension that can handle web scraping and data extraction tasks. You can scrape data directly within their browser. DataMiner supports both simple and complex Twitter scraping tasks. DataMiner also offers free plans with basic functionalities.
Features:
1. Browser extension for Chrome and Firefox.
2. Point-and-click interface for data selection.
3. Export data to CSV or Excel.
How to Use:
1. Install the DataMiner extension.
2. Navigate to Twitter and open the DataMiner extension.
3. Use the interface to select the data you want to scrape.
4. Export the scraped data.
When scraping data from Twitter, you can extract various types of information.

For Copy:
for tweet in tweepy.Cursor(api.search_tweets, q='#YourHashtag', lang='en').items(100):
print(tweet.text)
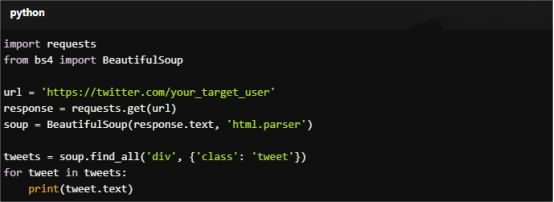
For Copy:
import requests
from bs4 import BeautifulSoup
url = 'https://twitter.com/your_target_user'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
tweets = soup.find_all('div', {'class': 'tweet'})
for tweet in tweets:
print(tweet.text)
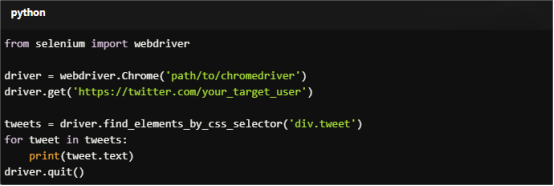
For Copy:
from selenium import webdriver
driver = webdriver.Chrome('path/to/chromedriver')
driver.get('https://twitter.com/your_target_user')
tweets = driver.find_elements_by_css_selector('div.tweet')
for tweet in tweets:
print(tweet.text)
driver.quit()

For Copy:
user = api.get_user(screen_name='username')
print(user.name, user.description, user.followers_count)
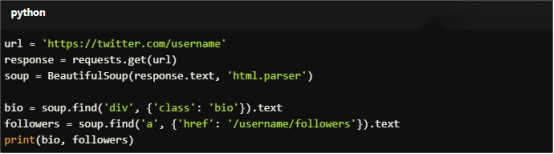
For Copy:
url = 'https://twitter.com/username'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
bio = soup.find('div', {'class': 'bio'}).text
followers = soup.find('a', {'href': '/username/followers'}).text
print(bio, followers)
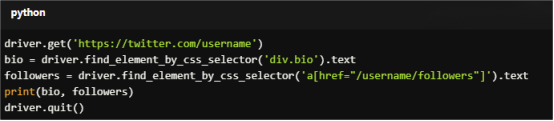
For Copy:
driver.get('https://twitter.com/username')
bio = driver.find_element_by_css_selector('div.bio').text
followers = driver.find_element_by_css_selector('a[href="/username/followers"]').text
print(bio, followers)
driver.quit()

For Copy:
trends = api.get_place_trends(id=1) # 1 for worldwide trends
for trend in trends[0]['trends']:
print(trend['name'])
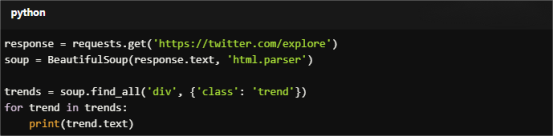
For Copy:
response = requests.get('https://twitter.com/explore')
soup = BeautifulSoup(response.text, 'html.parser')
trends = soup.find_all('div', {'class': 'trend'})
for trend in trends:
print(trend.text)
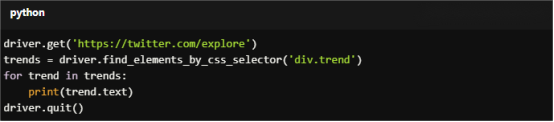
For Copy:
driver.get('https://twitter.com/explore')
trends = driver.find_elements_by_css_selector('div.trend')
for trend in trends:
print(trend.text)
driver.quit()

For Copy:
for tweet in tweepy.Cursor(api.search_tweets, q='#YourHashtag', lang='en').items(100):
if 'media' in tweet.entities:
for media in tweet.entities['media']:
print(media['media_url'])
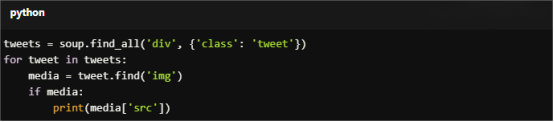
For Copy:
tweets = soup.find_all('div', {'class': 'tweet'})
for tweet in tweets:
media = tweet.find('img')
if media:
print(media['src'])
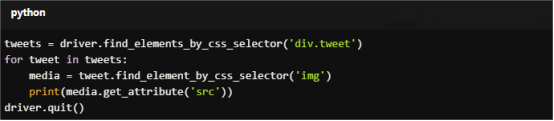
For Copy:
tweets = driver.find_elements_by_css_selector('div.tweet')
for tweet in tweets:
media = tweet.find_element_by_css_selector('img')
print(media.get_attribute('src'))
driver.quit()

For Copy:
for tweet in tweepy.Cursor(api.search_tweets, q='#YourHashtag', lang='en').items(100):
print(tweet.retweet_count, tweet.favorite_count)
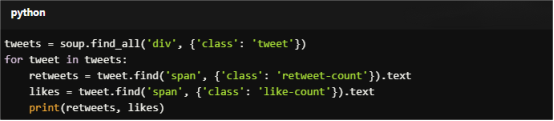
For Copy:
tweets = soup.find_all('div', {'class': 'tweet'})
for tweet in tweets:
retweets = tweet.find('span', {'class': 'retweet-count'}).text
likes = tweet.find('span', {'class': 'like-count'}).text
print(retweets, likes)
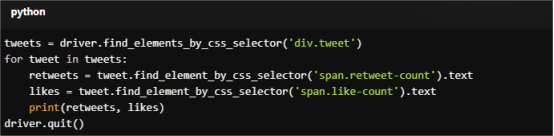
For Copy:
tweets = driver.find_elements_by_css_selector('div.tweet')
for tweet in tweets:
retweets = tweet.find_element_by_css_selector('span.retweet-count').text
likes = tweet.find_element_by_css_selector('span.like-count').text
print(retweets, likes)
driver.quit()
Twitter has anti-scraping mechanisms like CAPTCHA, IP bans, and rate-limiting. To scrape safely:

For Copy:
proxies = {"http": "http://proxy_ip:proxy_port", "https": "http://proxy_ip:proxy_port"}
response = requests.get("https://twitter.com", proxies=proxies)
print(response.text)

For Copy:
import time
import random
time.sleep(random.uniform(1, 5)) # Wait between 1 to 5 seconds
Scrape early mornings or late nights to reduce detection risks.

For Copy:
options.add_argument("--headless") # Prevents detection
When scraping data from Twitter, especially large-scale or frequent tasks, you may encounter challenges such as IP blocking, rate limiting, and CAPTCHAs. So, using rotating residential proxies like MacroProxy can help you avoid these issues. By integrating MacroProxy with your Twitter scraping scripts or tools, you can enjoy continuous and reliable data extraction without getting blocked.
MacroProxy Features:
1. A large pool of IP addresses from various geographic locations.
2. High-speed proxies to minimize delays in data scraping.
3. Easy integration with your scraping scripts or tools via API.
How to Use:
1. Visit the MacroProxy website and sign up for an account. Then choose a subscription plan.
2. Obtain the proxy details (IP addresses, ports, and authentication credentials).
3. Integrate the proxy details into your scraping script or configure your tool to use proxies.
4. Start the task.
Scraping Twitter can provide valuable insights—but it must be done responsibly:
Need residential proxies for Twitter scraping? Register and contact us with your tasks. Test chance for your worry-free purchase.
< Previous
Next >

Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29

Discover top web scraping tools for 2025, comparing features, proxy integration, and scalability to optimize your data extraction efforts.
Post Time:2025-04-25
Explore web scraping with JavaScript: tools, steps, and MacroProxy solutions for dynamic data extraction.
Post Time:2025-04-18