








3 Methods to Set Up a Reverse Proxy on a Home Network
Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29
Learn More
Discover everything you need to know about web scraping proxies, including what they are, why they matter, how to choose the best proxy and use them for efficient web scraping.
Web scraping is essential for gathering data from websites, enabling businesses and researchers to extract insights and make data-driven decisions. However, web scraping can often be challenging, especially when facing IP bans or rate limits. Web scraping proxies help users achieve smooth and anonymous data extraction.
What exactly is a web scraping proxy, and why is it essential for your web scraping projects? In this comprehensive guide, we’ll explore everything you need to know about web scraping proxies—from their benefits and use cases to tips on choosing the perfect proxy for your needs.

Web scraping proxy is not a type of proxies but proxies for web scraping tasks. It acts as an intermediary between your web scraper and the target website, routing requests through a proxy so that you can mask your IP address, avoid rate limits, and bypass restrictions. Proxies are crucial for successful web scraping, especially when dealing with websites that block repeated requests.
Without proxies, large-scale web scraping is nearly impossible due to the anti-bot measures most websites employ. It comes with its own challenges, and proxies can solve:
1. IP Blocking by Target Websites
Proxies help avoid bans by rotating IPs.
2. CAPTCHA Challenges
Proxies can facilitate CAPTCHA-solving methods, allowing for uninterrupted scraping.
3. Rate Limits and Request Throttling
Proxies allow you to distribute requests over multiple IPs, helping you stay under rate limits.
4. Geo-Restrictions
Proxies enable access to localized data by providing IPs from specific regions.
5. Anonymity
Safeguard your identity by using proxies instead of your real IP address.
While web scraping is a powerful tool, it’s essential to respect the terms of service of the websites you scrape and avoid scraping sensitive or personal data. Always use proxies responsibly.
Choosing the right proxy type for web scraping depends on your specific needs, including budget, required speed, and anonymity level.
1. Residential Proxies
Residential proxies use IP addresses assigned by Internet Service Providers (ISPs) to real residential addresses. Appear as legitimate user traffic.
Pros:
Cons:
2. Datacenter Proxies
Datacenter proxies come from data centers and are not linked to any ISP. They are created for high-speed access and are often used for less sensitive scraping tasks.
Pros:
Cons:
3. ISP Proxies
ISP proxies have the features of both residential and datacenter proxies. They use IPs from ISPs but are housed in data centers.
Pros:
Cons:
1. Dedicated Proxies
Dedicated proxies are exclusively assigned to a single user or organization.
Pros:
Cons:
2. Shared Proxies
Shared proxies are used by multiple users simultaneously.
Pros:
Cons:
Using proxies effectively in web scraping can significantly enhance your data extraction capabilities while minimizing the risk of IP bans. Here’s a detailed, actionable guide to implementing proxies in your web scraping projects.
Decide proxies based on your project. Consider factors like speed, reliability, and geographic location. As the former part we discussed.
For Python (Using requests or BeautifulSoup)
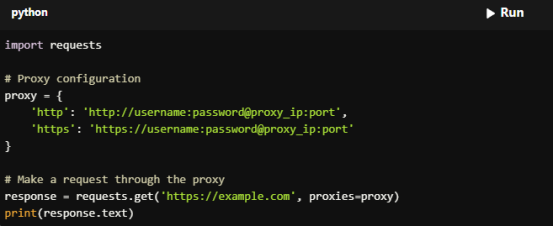 For Copy:
For Copy:
import requests
# Proxy configuration
proxy = {
'http': 'http://username:password@proxy_ip:port',
'https': 'https://username:password@proxy_ip:port'
}
# Make a request through the proxy
response = requests.get('https://example.com', proxies=proxy)
print(response.text)
For Scrapy
Add the proxy configuration to the Scrapy settings:
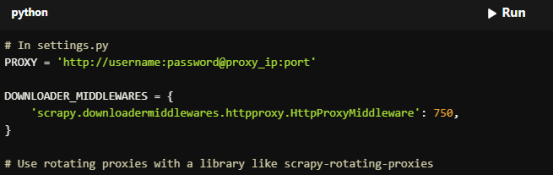
For Copy:
# In settings.py
PROXY = 'http://username:password@proxy_ip:port'
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
}
# Use rotating proxies with a library like scrapy-rotating-proxies
1. Use Proxy Rotation Tools
Implement tools like Scrapy Rotating Proxies or ProxyMesh for automatic IP rotation.
2. Rotate User Agents
For Python, libraries like Faker and random can change user agents and proxies, making your requests appear more like genuine user traffic.
1. Test Speed and Reliability
Check proxy performance regularly to ensure they are fast and stable.
2. Replace Slow or Blocked Proxies
Be proactive in maintaining your scraping efficiency by swapping out any slow or blocked proxies.
1. Proxy Blocking
Rotate proxies frequently and use high-quality residential proxies.
2. Slow Proxies
Opt for premium providers or datacenter proxies for faster speeds.
3. High Costs
Use shared proxies or a mix of proxy types to balance cost and performance.
To maximize the effectiveness of your web scraping proxies, consider these tips:
1. Rotate User Agents
Combine proxy rotation with random user agents to mimic real user behavior.
2. Respect Robots.txt
Check the website’s robots.txt file to avoid scraping restricted areas.
3. Use CAPTCHA-Solving Tools
Pair proxies with CAPTCHA-solving services like 2Captcha or Anti-Captcha.
4. Monitor Proxy Health
Regularly test proxies to ensure they are not blocked or slow.
5. Implement Rate Limiting
Control the number of requests sent to prevent detection.
6. Anonymize Data
Remove any personally identifiable information (PII) from your scraped data.
7. Use APIs Where Possible
Opt for official APIs to access data legally, if possible.
8. Adhere to Ethical Scraping Practices
Always adhere to ethical guidelines and avoid accessing private information. Familiarize yourself with the terms of service of the websites you scrape and check back regularly for updates.
Web scraping proxies are important to ensure efficient and reliable data extraction. By understanding the different types of proxies and how to use them effectively, you can overcome common scraping challenges and unlock the full potential of web scraping.
Ready to get started? Explore our web scraping proxies for your needs and start your scraping journey today! Free test before payment for your worry-free purchase.
1. What is a web scraping proxy?
A web scraping proxy is an intermediary server that masks your real IP address while scraping data, allowing for anonymity and reducing the risk of IP bans.
2. How do I choose the best proxy for web scraping?
Consider factors like speed, reliability, geographical coverage, and price. When choosing a proxy service, also consider customer support.
3. Can I use free proxies for web scraping?
While free proxies are available, they are often limited in speed and reliability which are crucial for scraping. Better to use a paid proxy service for serious scraping tasks.
4. How does AWS facilitate web scraping with proxies?
AWS provides scalable infrastructure, allowing you to run scraping scripts on EC2 instances while managing proxies efficiently.
5. How to set up proxies on aws for web scraping?
Here’s a concise guide:
Step 1: Create an AWS Account
Step 2: Launch an EC2 Instance
1. Go to the EC2 Dashboard.
2. Launch a New Instance.
Step 3: Connect to Your EC2 Instance
Use SSH to connect to your instance.
Command:
ssh -i your-key.pem ec2-user@your-instance-public-ip
Step 4: Install Required Software
Update the package manager and install necessary dependencies.
Command:
sudo yum update -y # For Amazon Linux
sudo apt-get update # For Ubuntu
sudo apt-get install python3 pip3
Step 5: Configure Proxy Settings
Command For Python scripts:
import requests
proxies = {
'http': 'http://username:password@proxy_ip:port',
'https': 'https://username:password@proxy_ip:port'
}
response = requests.get('https://example.com', proxies=proxies)
print(response.text)
Step 6: Run Your Scraping Script
6. What should I do if my proxies are not working?
Implement a fallback mechanism in your scraping script to switch to alternative proxies if the current ones fail, and monitor proxy performance regularly.
< Previous
Next >

Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29

Discover top web scraping tools for 2025, comparing features, proxy integration, and scalability to optimize your data extraction efforts.
Post Time:2025-04-25
Explore web scraping with JavaScript: tools, steps, and MacroProxy solutions for dynamic data extraction.
Post Time:2025-04-18