








3 Methods to Set Up a Reverse Proxy on a Home Network
Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29
Learn More
Learn how to effectively use web scraping proxy pools to avoid detection and bans, including key features, best practices, and step-by-step setup.
For web scraping, a big challenge is avoiding detection and bans. Websites implement increasingly sophisticated anti-bot mechanisms to block repeated requests from the same IP address in a short time, that's why scraping data at scale is difficult. A proxy pool is one of the most effective and affordable ways to overcome this challenge. You can rotate between multiple IP addresses, ensuring anonymity and enabling you to scrape data more efficiently without getting blocked.
In this guide, we will discuss how to set up a web scraping proxy pool, including what is a proxy pool, what is web scraping, how to choose proxies for the pool, and how to set up for optional performance.
A proxy pool is a collection of proxy servers used to interchangeably route internet traffic. Using it, individuals and businesses can effectively manage their online activities while minimizing risks associated with IP bans and tracking. This is especially beneficial for web scraping and data mining.
Key Features
Web scraping refers to the automated process of extracting data from websites. It is a powerful technique widely used for gathering web information. Common use cases such as market research, data analysis, SEO monitoring, etc.
The scraping process involves:
1. Web Crawling: A program (crawler or spider) navigates the internet to discover and retrieve web pages.
2. Data Extraction: Web scraping tools parse the webpage HTML or XML content to extract required structured information, including text, images, links, etc.
3. Data Storage: Typically stored in a structured format(e.g. database, CSV file, spreadshee) for further analysis or processing.
It’s essential to use web scraping responsibly and consider legal & ethical implications.
Websites use anti-bot measures like CAPTCHAs, rate-limiting, and IP blacklisting to block scrapers. If you’re scraping data at scale, using a single IP address can quickly lead to detection. That's why you need a proxy pool.
Before setting up your proxy pool, it’s important to choose the right type of proxies for your scraping needs. Here are the most common types:
1. Residential Proxies
Assigned by ISPs to real devices (e.g., home users).
Best for: E-commerce sites, social media, and other sensitive targets.
2. Datacenter Proxies
Generated from data centers, not tied to physical devices.
Best for: Non-sensitive or low-security websites.
3. Rotating Proxies
Automatically switch IPs after each request or session.
Best for: Large-scale scraping projects.
4. Free Proxies
Publicly available but often unreliable and insecure.
Best for: Learning or testing purposes (not recommended for production).
Setting up a proxy pool can be done using Python and popular libraries like requests or Scrapy. Here’s a step-by-step guide:
For this tutorial, we’ll use Python. Install the following libraries:
Install the required libraries using pip:

For Copy:
pip install requests
Start by creating a list of proxies. Replace the placeholders with actual proxy addresses.
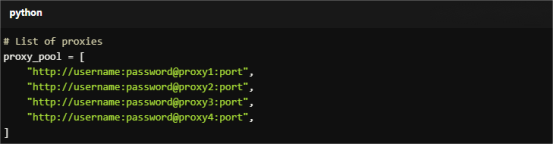
For Copy:
# List of proxies
proxy_pool = [
"http://username:password@proxy1:port",
"http://username:password@proxy2:port",
"http://username:password@proxy3:port",
"http://username:password@proxy4:port",
]
Use the random library to select a proxy from the pool for each request.
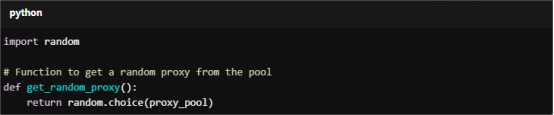
For Copy:
import random
# Function to get a random proxy from the pool
def get_random_proxy():
return random.choice(proxy_pool)
Here’s an example of using the proxy pool to scrape a website:
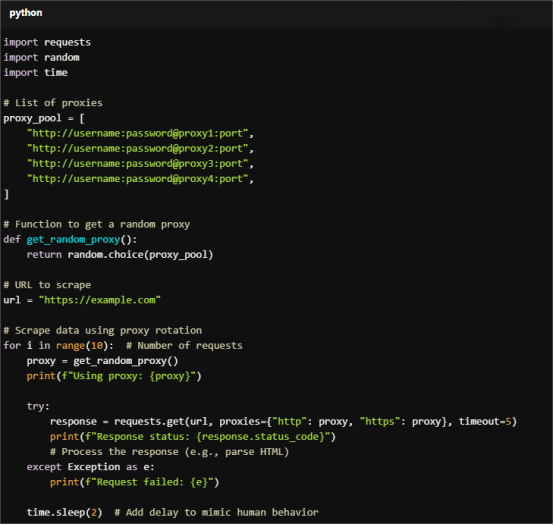
For Copy:
import requests
import random
import time
# List of proxies
proxy_pool = [
"http://username:password@proxy1:port",
"http://username:password@proxy2:port",
"http://username:password@proxy3:port",
"http://username:password@proxy4:port",
]
# Function to get a random proxy
def get_random_proxy():
return random.choice(proxy_pool)
# URL to scrape
url = "https://example.com"
# Scrape data using proxy rotation
for i in range(10): # Number of requests
proxy = get_random_proxy()
print(f"Using proxy: {proxy}")
try:
response = requests.get(url, proxies={"http": proxy, "https": proxy}, timeout=5)
print(f"Response status: {response.status_code}")
# Process the response (e.g., parse HTML)
except Exception as e:
print(f"Request failed: {e}")
time.sleep(2) # Add delay to mimic human behavior
Sometimes, a proxy may fail or get blocked. Implement error handling to retry with a different proxy:
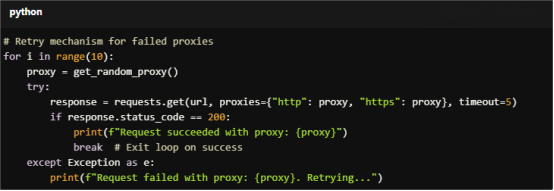
For Copy:
# Retry mechanism for failed proxies
for i in range(10):
proxy = get_random_proxy()
try:
response = requests.get(url, proxies={"http": proxy, "https": proxy}, timeout=5)
if response.status_code == 200:
print(f"Request succeeded with proxy: {proxy}")
break # Exit loop on success
except Exception as e:
print(f"Request failed with proxy: {proxy}. Retrying...")
If you don’t want to build your own proxy pool, consider using:
1. What is the best type of proxy for web scraping?
Residential proxies are the best for high-security websites, while datacenter proxies are suitable for low-security targets. Rotating proxies are ideal for large-scale scraping.
For large-scale and secure scraping, consider rotating residential proxies to ensure performance.
2. How many proxies do I need in a pool?
The number of proxies depends on your scraping scale. For small projects, 10-20 proxies may suffice. For large-scale scraping, hundreds or thousands of proxies may be needed.
3. Can I use free proxies for web scraping?
Free proxies are often slow, unreliable, and prone to blocking. They are not recommended for production scraping.
4. How often should I rotate proxies?
Rotate proxies after every request or every few requests to minimize detection risks.
A web scraping proxy pool is an essential tool for scaling your scraping efforts while avoiding detection and bans. By rotating proxies, using high-quality IPs, and following best practices, you can scrape data efficiently and anonymously.
Whether you’re scraping e-commerce data, social media profiles, or other web content, setting up a robust proxy pool will significantly improve your success rate. Start building your proxy pool today and take your web scraping projects to the next level!
< Previous
Next >

Step-by-step guide to install and configure NGINX, Apache, or Caddy as a reverse proxy for home servers, complete with SSL, security, and troubleshooting tips.
Post Time:2025-04-29

Discover top web scraping tools for 2025, comparing features, proxy integration, and scalability to optimize your data extraction efforts.
Post Time:2025-04-25
Explore web scraping with JavaScript: tools, steps, and MacroProxy solutions for dynamic data extraction.
Post Time:2025-04-18